▶ 빅데이터 기술을 분류하면 순서에 따라 다음과 같이 분류할 수 있다.
①빅데이터 수집 ▶ ②빅데이터 저장 ▶ ③빅데이터 분석 ▶ ④빅데이터 시각화
① 빅데이터 수집
- 내부 데이터의 수집 : 자체적으로 보유한 내부 파일 시스템이나 데이터베이스 관리 시스템, 센서 등에 접근하여 정형 데이터를 수집함
- 외부 데이터의 수집 : 인터넷으로 연결된 외부에서 (주로)비정형 데이터를 수집함
- 데이터 수집 : 주로 툴이나 프로그래밍으로 자동 진행됨
☞ 로그 수집기, 웹 크롤링 툴, 오픈 API, ETL(Extraction[추출], Transformation[변환], Loading[적재]) 등의 수집 방법을 사용함
②빅데이터 저장
- 추후 사용될 수 있도록 데이터를 안전하고 효율적으로 저장하는 기술
- 대량의 데이터를 파일 형태로 저장하는 기술과 비정형 데이터를 정형화된 데이터 형태로 저장하는 기술이 필요함
- 분산 파일 시스템[GFS, HDFS 등], NoSQL, 병렬 DBMS, 네트워크 기반 저장 시스템[NAS, SAN 등] 등의 기술을 이용함
③빅데이터 분석
- 데이터 마이닝, 머신러닝 등의 알고리즘을 대규모 데이터 처리에 맞게 개선하여 빅데이터 처리에 적용함
- R, 파이썬, Mahout(머하웃) 등을 이용함
| 텍스트 마이닝(Text Mining) | 자연어 처리 기술을 이용하여 비정형 텍스트에서 유용한 정보를 추출하거나 다른 데이터와의 연계성 파악 |
| 웹 마이닝(Web Mining) | 인터넷에서 수집한 정보를 분석 |
| 오피니언 마이닝 (Opinion Mining) | 다양한 온라인 뉴스와 소셜 미디어 코멘트, 사용자가 만든 콘텐츠에서 의견을 추출하고 분석 |
| 소셜 네트워크(SNS) 분석 (Social Network Analysis) | 소셜 네트워크 서비스에서 수학의 그래프 이론을 바탕으로 연결 구조와 연결 강도를 분석 |
④빅데이터 시각화
- 분석된 결과를 한눈에 쉽게 이해핦 수 있도록 직관적인 표현으로 시각화하는 기술
- D3.js, Tableau, R, 파이썬 등을 이용하여 시각화

하둡과 맵리듀스
1) 하둡의 개요
● 하둡
| 대용량 데이터를 분산 처리할 수 있는 자바 기반의 오픈소스 프레임워크 |
==> 아파치(Apache)의 검색엔진 프로젝트인 루씬(Lucene)의 서브 프로젝트로 진행되었지만 2008년 1월에 아파치의 최상위 프로젝트로 승격됨

● 하둡은 루씬의 창시자인 더그 커팅이 개발하고 오픈소스로 공개

● 분산 파일 시스템인 HDFS(Hadoop Distributed File System)에 데이터를 저장함
● 분산 처리 시스템인 맵리듀스를 이용해 데이터를 처리함
● 하둡(Hadoop)의 장점
√ 비정형 데이터를 RDBMS에 저장하기에는 데이터가 너무 크고 비용이 많이 듦
√ 하둡은 오픈소스 프로젝트이므로 라이선스 비용의 부담이 없음
√ 여러 대의 서버에 데이터를 분산 저장하고, 데이터가 저장된 각 서버에서 동시에 데이터를 처리가 가능하다
√ 저렴한 구축 비용, 빠른 데이터 처리, 장애가 발생해도 처리가 가능하다.
● 하둡 에코시스템(EcoSystem)
" 하둡은 비즈니스에 효율적으로 적용할 수 있는 다양한 서브 프로젝트를 제공한다. "
* Hadoop의 메인 프로젝트는 HDFS와 MapReduce 이다.
| 분산 코디네이트 | Zookeeper |
| 리소스 관리 | Yarn, Mesos |
| 데이터 저장 | HBase, Kudu |
| 데이터 수집 | Chukwa, Flume, Scribe, Kafka |
| 데이터 처리 | Pig, Mahout, Spark, Impale, Hive |
● 하둡 에코시스템(EcoSystem)

● 하둡 분산 파일 시스템 (HDFS)
| 대용량의 파일을 분산된 서버에 저장하고, 저장된 데이터를 빠르게 저장할 수 있게 설계된 파일 시스템 |
- 안정성 : 데이터를 저장하면 다수의 노드에 복제 데이터도 함께 저장하여 유실을 방지
- 스트리밍 방식 : 스트리밍 방식으로 데이터에 접근하도록 설계되어 있으므로 끊김없이 연속된 흐름으로 데이터에 접근
- 대용량 데이터 저장 : 하나의 파일이 기가바이트에서 테라바이트 이상의 크기로 저장할 수 있도록 설계
- 무결성 : 한 번 저장된 데이터는 수정할 수 없고, 파일 이동, 삭제, 복사만 가능
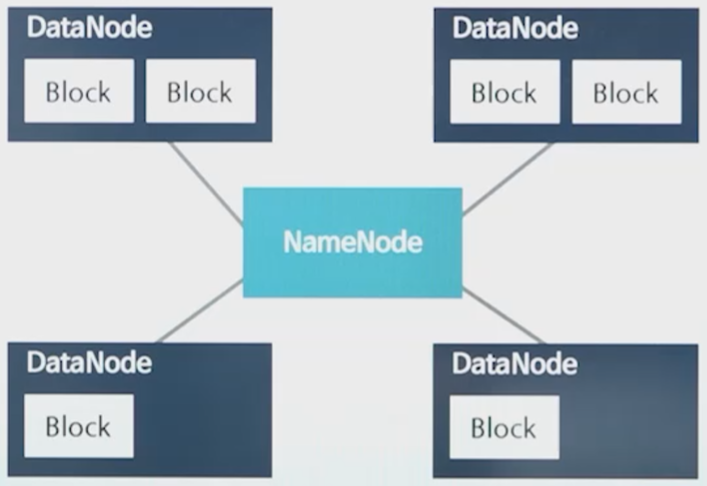
● HDFS의 구성

▶ NameNode : 마스터 역할을하는 노드로 파일 시스템의 이름 공간을 관리하면서 클라이언트로부터의 파일 접근 요청을 처리
▶ DataNode : 파일 데이터를 블록 단위로 나누어 여러 데이터 노드에 분산 저장, 슬레이브 노드라고도 불리움
● HDFS의 파일 저장 순서
① 클라이언트가 네임노드에게 파일 저장을 요청한다.(파일을 저장하기 위한 스트림 생성)
② 클라이언트가 데이터노드에게 패킷을 전송.(클라이언트가 네임노드에게 파일 제어권을 얻으면 데이터 노드에게 파일을 패킷 단위로 나누어서 전송)
③ 클라이언트가 파일 저장을 완료 (스트림을 닫고 파일 저장을 완료)
★ 맵리듀스(MapReduce)
- HDFS에 저장된 파일을 분산 배치 분석을 할 수 있게 도와주는 프레임워크
- 분할 정복 방식으로 대용량 데이터를 병렬로 처리할 수 있는 프로그래밍 모델
☞ 구글에서 맵리듀스 방식의 분산 컴퓨팅 플랫폼을 구현해 성공적으로 적용함으로서 유명해짐
| "오픈 소스인 Hadoop MapReduce 프레임워크가 동일한 기능을 지원" |
● 맵리듀스의 개요
| MapReduce는 Map과 Reduce 2개의 함수 기반으로 구성된다. |
- Map : 입력의 <키, 값>을 새로운 <키,값>으로 변환한다.
- Reduce : 시스템이 수집한 <키, (값1, 값2, ...) >을 다시 <키, 값>으로 변환하여 HDFS에 저장한다.
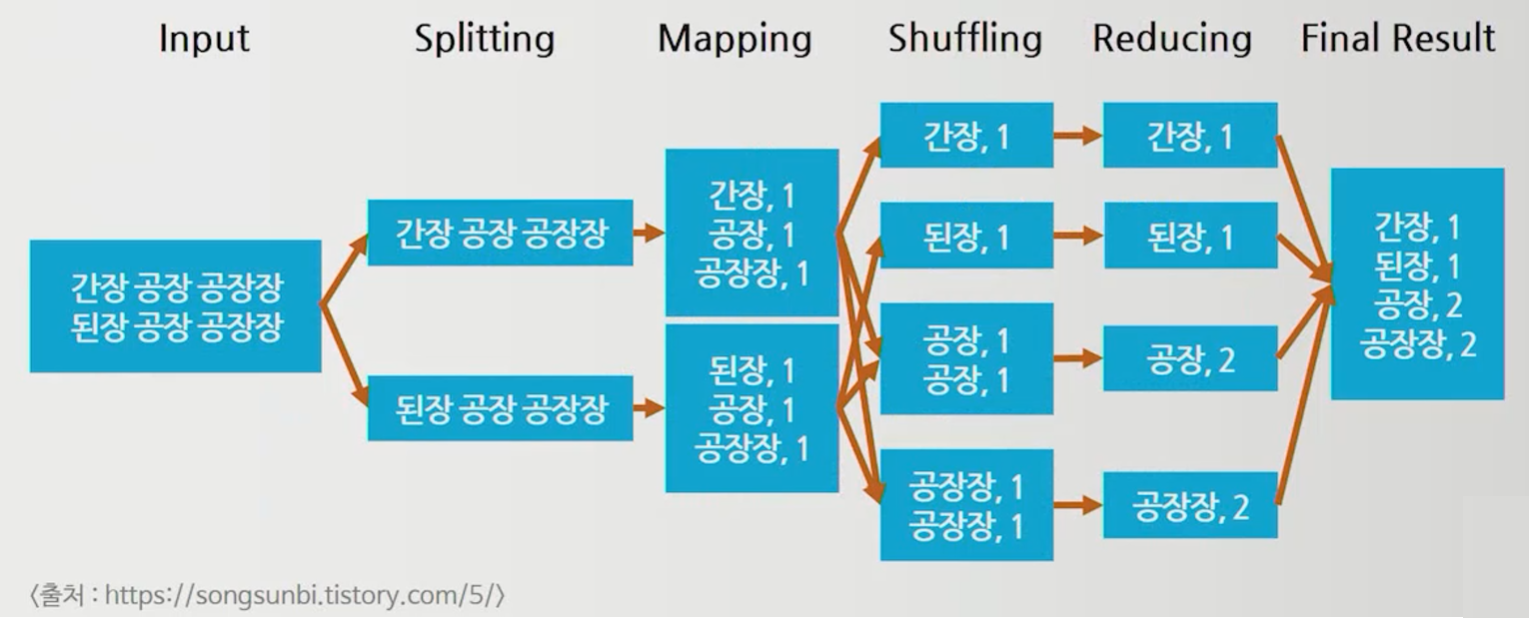
▤ Splitting : 입력 데이터 파일을 입력 스플릿(InputSplit)이라는 크기의 조각으로 분리함
▤ Mapping : 입력 스플릿의 데이터를 한 줄씩 읽어서 맵 함수를 실행 => 맵 함수는 <키, 값>을 출력함
▤ Shuffling : 맵 태스크의 출력 데이터가 리듀스 태스크에게 전달되는 과정으로 같은 키를 가지는 데이터끼리 분류함
▤ Reducing : 사용자에게 전달할 출력 파일을 생성하며, 리듀스 함수는 키별로 값의 목록을 합산하여 출력함
▤ Final Result : 리듀스 함수의 출력 데이터를 합쳐서 HDFS에 저장함
● 빅데이터 저장기술의 개요
- 빅데이터는 '대용량, 비정형(다양성), 실시간성' 속성을 수용할 수 있는 저장 방식이 필요하다.
- 네트워크상에서 데이터를 저장 · 조회 · 관리할 수 있는 기능을 제공해야 함
- 병렬 DBMS, NoSQL, 분산 파일 시스템(HDFS) 등의 기술을 사용할 수 있음
● RDBMS (데이터베이스의 정의)
| 문자, 기호, 음성, 화상, 영상 등 상호 관련된 다수의 콘텐츠를 정보 처리 및 정보통신 기기에 의하여 체계적으로 수집/축적하여 다양한 용도와 방법으로 이용할 수 있도록 정리한 정보의 집합체 <출처: 데이터 분석 전문가 가이드> |
● 데이터베이스의 특성
- 통합된 데이터(Integrated Data) ==> 데이터베이스에서 동일한 내용의 데이터가 중복되어 있지 않음(중복성을 최대한 제거)
- 저장된 데이터(Stored Data) ==> 컴퓨터가 접근할 수 있는 저장 매체에 저장
- 공용 데이터(Shared Data) ==> 여러 사용자가 서로 다른 목적으로 데이터베이스의 데이터를 공동으로 이용
- 변화되는 데이터(Changable Data) ==> 삽입, 삭제, 갱신으로 항상 변화하면서도 항상 현재의 정확한 데이터를 유지
● 관계형 데이터베이스 관리 시스템
☞ DBMS
| 사용자와 데이터베이스 사이에 위치하여 데이터베이스를 정의하고, 사용자의 요구에 따라 데이터베이스에 대한 연산을 수행해서 정보를 생성하며, 접근 방법의 통제를 통해 데이터의 무결성을 유지 관리하는 소프트웨어 |
☞ 관계형 데이터베이스 관리 시스템(RDBMS: Relational Database Management System)
| 행과 열로 된 2차원의 표로 데이터를 표현하는 데이터베이스 관리 시스템 |

★ NoSQL (전통적인 SQL을 사용하지 않는 방식)
● CAP 이론

● NoSQL 특징
- 카를로 스트로찌(Carlo Strozzi)는 1998년 표준 SQL 인터페이스를 채용하지 않은 자신의 경량 오픈 소스
'Cloud > BigData' 카테고리의 다른 글
| Introduction to Hadoop (0) | 2023.10.09 |
|---|
